The Canteen Builder Graph: Finding Builder Talent
The Canteen Builder Graph: Finding Builder Talent at Scale
The best developers aren’t always the most visible ones. Great talent gets buried in GitHub’s noise - thousands of commits, millions of PRs, endless repositories. Finding the right person for a project usually means endless LinkedIn searches, hoping someone mentions the right keywords in their profile.
We built something leveraging the power of the bipartite graph!
What We Built
The Canteen Builder Graph is a search system that understands developers by what they’ve actually built, not what they claim to know. We analyze ~1M developers and ~500k repositories to:
- Surface new builder talent that traditional recruiting misses
- Find clusters of builder energy around specific technologies and problems
- Evaluate the nature and quality of a developer’s contributions
Instead of keyword matching, we use the graph of who’s contributed to what to find semantic relationships between developers and projects.
How It Works: A Real Example
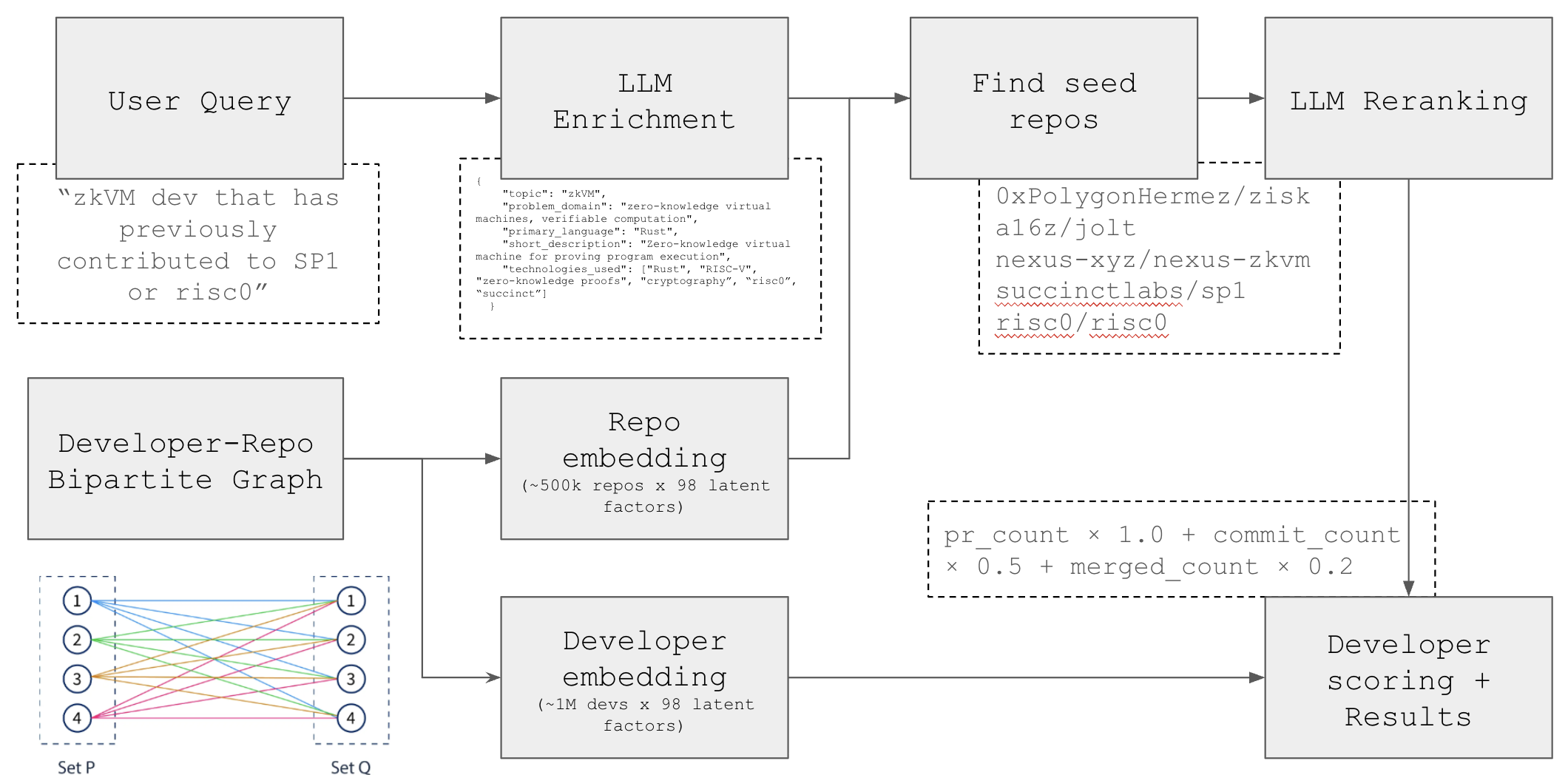
Say you need to find “zkVM devs who’ve contributed to SP1 or risc0”. Here’s what happens:
Understanding the Query
We use an LLM to expand your query into a richer understanding of what you’re actually looking for:
{
"topic": "zkVM",
"problem_domain": "zero-knowledge virtual machines, verifiable computation",
"primary_language": "Rust",
"technologies_used": ["Rust", "zkEVM"],
"tags": ["zero-knowledge proofs", "cryptography", "risc0", "succinct"]
}
This helps us think beyond just the literal keywords.
Finding the Right Repositories
We identify the core zkVM projects in our graph:
These become our starting points.
The Magic: Understanding Developer DNA
Here’s where it gets interesting. We’ve built a graph connecting every developer to every repository they’ve contributed to - weighted by their actual work (PRs, commits, merges).
Then we use SVD decomposition to compress this massive graph into something we can actually search. Each developer and each repository gets a “fingerprint” - a vector that captures what they’re about.
The cool part: developers who work on similar things end up with similar fingerprints, even if they’ve never contributed to the exact same projects. A developer who’s deep in Jolt probably has a lot in common with someone working on SP1, even if they’ve never touched the same codebase.
Finding Your People
We compare our seed repositories (SP1, risc0, etc.) against all ~1M developer fingerprints. This surfaces three groups:
- Direct contributors: Devs who’ve actually worked on SP1 or risc0
- Adjacent talent: People who’ve built similar things in related projects
- Hidden gems: Developers with the right technical profile who you’d never find with keyword search
Quality Over Quantity
Not all contributions are equal. We score developers by what they’ve actually shipped:
score = pr_count × 1.0 + commit_count × 0.5 + merged_count × 0.2
But we go deeper than just counting commits. We analyze the actual content:
- What did they build? Looking at PR descriptions, commit messages, and code changes to understand complexity and impact
- How do they work? Evaluating technical communication and problem-solving from review discussions
- What’s their signature? Understanding patterns in their contributions
This is how we distinguish between someone who made 500 trivial commits and someone who shipped 5 features that matter.
Final Ranking
An LLM does the final ranking, weighing:
- How well do they match what you’re actually looking for?
- Are they actively building, or was their last commit 3 years ago?
- How deep is their expertise in this specific domain?
- What’s the pattern of their contributions?
Why This Matters
Traditional recruiting is broken. LinkedIn searches find people who are good at SEO, not people who are good at building. GitHub’s native search is keyword matching at best.
We built the Builder Graph to solve three problems:
1. Surface New Builder Talent
The best developers are often invisible. They’re grinding on open source, shipping features, solving hard problems - but they don’t have 10k Twitter followers or a polished LinkedIn. Our system finds them by what they’ve actually built.
2. Find Clusters of Builder Energy
Where is the talent concentrated? Who’s working on zkVMs? Where are the top MEV developers? We can map entire ecosystems, showing you where the energy is and who the key contributors are.
3. Evaluate Developer Contributions
Not all commits are equal. We go beyond GitHub stars and commit counts to understand the nature and quality of someone’s work. Are they building core infrastructure or fixing typos? Are they shipping features or just filing issues?
This is how we think talent discovery should work: based on what you’ve built, not what you claim to know.